
Jakość danych jest kluczowym czynnikiem, od którego zależy sukces wszystkich przedsięwzięć i projektów opartych na danych. Efektywna optymalizacja i diagnoza infrastruktury wymaga poprawnych informacji z procesów i urządzeń. Nic dziwnego, że osoby odpowiedzialne za data science poświęcają blisko 80% czasu na samo przygotowanie danych.
W celu osiągnięcia zadowalającej jakości danych niezbędna jest ich inteligentna walidacja. „Inteligentna” nie oznacza od razu zastosowania zaawansowanych algorytmów machine learning. W pierwszej kolejności należy podjąć próbę wykorzystania metod obliczeniowych: wzorów matematycznych, fizycznych, chemicznych oraz wiedzy branżowej.
Inteligentna walidacja nie oznacza automatycznie użycia zaawansowanych algorytmów uczenia maszynowego. Zacznij od fizyki i matematyki.
Do tego zadania niezbędne są odpowiednie narzędzia takie, jak programy analityczne w chmurze. Dobre narzędzie powinno radzić sobie z time-series data (wiele odczytów z jednego urządzenia), umożliwiać wykorzystanie różnorodnych algorytmów - od prostych obliczeniowych do zaawansowanych metod statystycznych oraz być intuicyjne i skalowalne. Warto zaznaczyć, że nie spełnia tych warunków popularny Excel. Wśród rozwiązań ConnectPoint na pewno sprawdzi się Smart RDM w oraz narzędzie partnera Seeq.
Skąd biorą się błędy w danych?
Powodów złej jakości danych jest kilka. Należą do nich nieodpowiednio przeprowadzone wdrożenia oprogramowania, które skutkują błędami lub niewłaściwą obsługą poszczególnych przypadków, na przykład zła konfiguracja systemu DCS/SCADA.
Inną przyczyną mogą być problemy na poziomie systemowym. Dzieje się tak, gdy źródłem danych są układy telemetryczne, a odczyty są pobierane z realnych urządzeń, które jak wiemy lubią się psuć. Często błędy tworzą się więc już na etapie pomiaru lub przekazania wartości do systemu nadrzędnego. Powszechnie występują np: błędy w transmisji, luki w danych oraz nieprawidłowe wartości – anomalie w odczytach. Czujniki mogą ulec uszkodzeniu, co skutkuje odbiorem absurdalnych wartości.
Uszkodzony może być też sam system przesyłania danych, który został źle wyskalowany lub w którym wymieniono urządzenie. Kolejną przyczyną złej jakości są zmiany w formacie danych, wpływające na źródła lub docelowe magazyny danych.
Etapy czyszczenia danych
Zebranie idealnych danych nie jest możliwe. Jak więc je oczyścić, by nie doprowadziły nas do mylnych interpretacji i wniosków? Trzeba przejś przez wszystkie etapy czyszczenia danych:
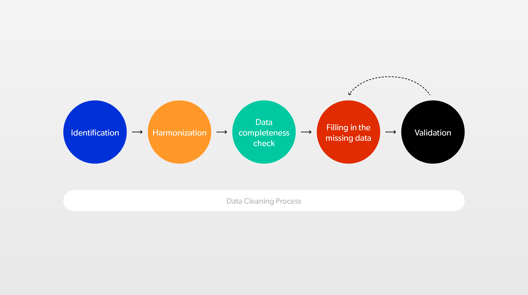
1. Identyfikacja — służy do określenia, które dane pochodzą z którego urządzania. Na przykład jeden węzeł cieplny może mieć 5 mierników temperatury i 2 sensory pomiarów przepływu. Nie możemy przypadkowo korzystać z danych dostarczanych przez czwarty miernik, jeśli akurat potrzebne były te z pierwszego. Musimy wiedzieć, który jest który. W tym celu przypisujemy dane do odpowiednich urządzeń w sposób umożliwiający ich poprawną identyfikację i organizujemy w strukturę drzewa.
2. Harmonizacja — urządzenia różnych producentów używają innego kodowania, sposobu przesyłu danych, a nawet jednostek. Celem harmonizacji jest sprowadzenie wszystkich danych do wspólnego formatu i wprowadzenie nazewnictwa opartego na znormalizowanym systemie kodowania.
3. Sprawdzenie kompletności danych —musimy upewnić się, których danych brakuje i dlaczego. Nie ma sensu szacować odczytów dla urządzenia, które w danym momencie było planowo wyłączone np. z powodu konserwacji. Zidentyfikowane luki w danych wymagających wypełnienia są szacowane w kolejnych krokach procesu.
4. Wypełnienie brakujących danych —w tym celu możemy zastosować różne metody: zaczynając od obliczeniowych, przez statystyczne, po machine learning.
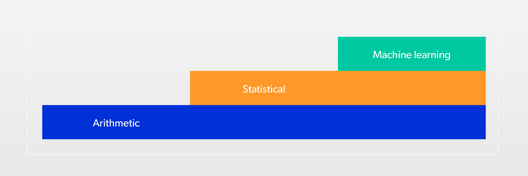
W przypadku metody obliczeniowej, brakujące dane liczymy na podstawie pozostałych danych za pomocą działań arytmetycznych, wzorów fizycznych etc. Możemy użyć też aproksymacji liniowej, tzn. połączyć linią ostatnią daną jaką mieliśmy, z pierwszą, która się pojawia. Użycie trendu liniowego jest najprostsze, niestety często prowadzi do błędu.
Dlatego dobrym wyjściem jest zastosowanie metody statystycznej, tzn. liczymy na podstawie wcześniejszych danych, jakie dane teoretycznie powinny występować w określonym miejscu i używamy ich do wypełnienia luki. Jest to szczególnie przydatne w przypadku zjawisk, których nie jesteśmy w stanie opisać za pomocą formuł obliczeniowych. Przykładowo, gdy chcemy znaleźć zależność między prędkością wiatru, a wibracjami turbiny wiatrowej pracującej na farmie wiatrowej w sąsiedztwie innych turbin. Wtedy znaczenia nabiera chociażby kierunek wiatru, ponieważ turbiny zasłaniają się i wzajemnie zakłócają przepływ powietrza.
Możemy także wspomóc się modelami wykorzystującymi uczenie maszynowe. Modele te uczą się typowego zachowania maszyn opierając się na danych historycznych. Na podstawie analizy zdarzeń występujących w przeszłości, model próbuje przewidzieć jak maszyna zachowywała się w okresach, w których są luki w danych.
Alternatywnym sposobem może być analiza otoczenia – w analizowanej lokalizacji możemy użyć danych z sąsiednich – podobnych urządzeń. Na przykład, gdy wiemy, że budynki stoją obok siebie, temperatury otoczenia nie musimy liczyć statystycznie - wystarczy „podejrzeć sąsiada”. Budujemy logikę opartą na systemie, który policzy parametry na podstawie zachowania całej rodziny podobnych obiektów znajdujących się obok siebie. To najbardziej zaawansowane podejście.
Na tym etapie mamy już kompletny sygnał. W kolejnych krokach zajmiemy się sprawdzeniem jego prawidłowości.
5. Walidacja — wśród naszych danych mogą znajdować się dane fałszywe. Co ważne te dane są poprawne technicznie, ale nie pasują pod względem logicznym. Na przykład wiemy, że odczyt temperatury na zewnątrz zimą w Londynie nie może wynosić 120 stopni Celsjusza.
Tutaj ponownie, najpierw wykorzystujemy matematykę do ustalenia zasad walidacji i przyjmujemy, że temperatura na zewnątrz musi być w granicach, np. od -50 do +50 stopni Celsjusza. Następnie, dodajemy regułę mówiącą, że dane poza tym zakresem są niepoprawne.
Teraz to my tworzymy luki, które kolejno będziemy wypełniać. Sprawdzamy, czy dane znajdują się w rozsądnym zakresie lub czy nie zmieniają się zbyt szybko. Wszystkie dane wykraczające poza zakres uznajemy za nieprawidłowe.
Ponadto, możemy użyć modelu fizycznego lub chemicznego do wykluczenia nieprawidłowych wartości. Podstawiamy do wzoru dane i wyrzucamy te, które nie dają prawidłowych wyników. W celu uzupełnienia tych danych, postępujemy analogicznie jak w kroku, w którym wypełnialiśmy luki. Biorąc pod uwagę poziom skomplikowania danych i ich zależności, wykorzystujemy matematykę, statystykę i machine learning.
W procesie walidacji korzystamy z wiedzy branżowej, która pozwala odpowiednio oddać zachowanie danego urządzenia. Przykładowo, liczniki mają określony maksymalny zakres, po którego osiągnięciu przekręcają się na zero i zaczynają liczyć od nowa. Dzięki wiedzy eksperckiej, możemy ustawić zasadę walidacyjną, która szuka takich “przekręceń” i pozwala śledzić poprawnie przyrost danych.
Po wykonaniu wszystkich powyższych kroków, otrzymujemy czysty sygnał. Nasze poprawne dane pozwalają teraz na budowę skomplikowanych modeli, wykorzystujących zaawansowaną analitykę typu predictive maintenance. Modele te mogą służyć np. do wiarygodnej prognozy zapotrzebowania na energię lub bieżącą diagnostykę pracy urządzenia.
Dane historyczne
O ile w przypadku modeli matematycznych i fizycznych nie jest potrzebna historia pomiarów, tak w przypadku statystyki i machine learningu dane historyczne są niezbędne. Im więcej danych historycznych, tym skuteczniejsza będzie nasza walidacja.
Modele uczące się nie są nieomylne, dlatego najlepiej stosować je w przemyśle jako systemy wspomagające, a nie podejmujące decyzję. Natomiast im więcej danych historycznych taki system przyjmie, tym większa jego niezawodność i precyzyjność.
Do przetwarzania danych historycznych w kontekście walidacji potrzebne są dedykowane rozwiązania takie, jak Smartvee lub Seeq, które są przygotowane do analizowania danych w postaci szeregów czasowych (ang.tzw. time-series data) i umożliwiają analizy o różnym poziomie skomplikowania.
Dlaczego machine learning nie powinien być domyślną metodą?
Należy pamiętać, że uczenie maszynowe nie zastąpi termodynamiki, fizyki i matematyki. Najważniejsze jest poznanie zjawiska, które badamy. Budowę systemu należy rozpocząć od opisu znanych wydarzeń z uwzględnieniem tego, co wiemy z chemii, fizyki, biologii i innych dziedzin nauki. Dopiero po tym kroku, możemy uznać za właściwe wykorzystanie machine learning.
Należy pamiętać, że uczenie maszynowe nie zastąpi termodynamiki, fizyki i matematyki.
W tym celu organizujemy warsztaty biznesowe z zespołami pracującymi z infrastrukturą i urządzeniami. Dzięki temu możemy zobaczyć dane, ocenić występujące zjawiska i zapytać o przyczyny anomalii. Na warsztaty zapraszamy inżynierów, zespoły data science, przedstawicieli działów biznesowych i ekspertów branżowych.
Algorytm nie zawsze radzi sobie najlepiej z nowymi, niespotykanymi wcześniej problemami. Dlatego modele uczące się powinny skupiać się na modelowaniu rzeczy, których nie umiemy opisać wzorami. Przy mniej złożonych procesach są to metody nieoptymalne.
Efekty walidacji danych
Wyczyszczone dane są świetną bazą do wykonywania dalszych analiz, np. predykcji produkcji energii, zużycia surowców albo planowania działań konserwacyjnych. Niestety część firm zaczyna od analityki, pomijając ważny etap przygotowania danych. Pamiętajmy jednak, że bez dobrej jakości danych nie otrzymamy wiarygodnej analizy.
W ConnectPoint oferujemy kompleksowe rozwiązanie: od zebrania danych do zaawansowanej analizy. Budujemy Repozytorium Danych, które pozwala na identyfikację i harmonizację danych. Następnie tworzymy na nim kolejne warstwy analityczne dopasowane do potrzeb naszych Klientów. Napisz do nas i dowiedz się więcej o tym, jak możesz poprawić wykorzystanie danych w Twojej organizacji.
